從0開(kāi)始學(xué)大數(shù)據(jù)06 新技術(shù)層出不窮,HDFS依然是存儲(chǔ)的王者
引言
在大數(shù)據(jù)技術(shù)日新月異的今天,各種新型的存儲(chǔ)和處理框架層出不窮,例如云原生存儲(chǔ)、對(duì)象存儲(chǔ)、實(shí)時(shí)數(shù)據(jù)庫(kù)等。當(dāng)我們深入大數(shù)據(jù)生態(tài)系統(tǒng)的核心時(shí),會(huì)發(fā)現(xiàn)Hadoop分布式文件系統(tǒng)(HDFS)依然穩(wěn)坐“存儲(chǔ)王者”的寶座。為什么在新技術(shù)浪潮中,HDFS能保持其不可撼動(dòng)的地位?本文將帶你從數(shù)據(jù)處理和存儲(chǔ)服務(wù)的角度,一探究竟。
HDFS的核心優(yōu)勢(shì)
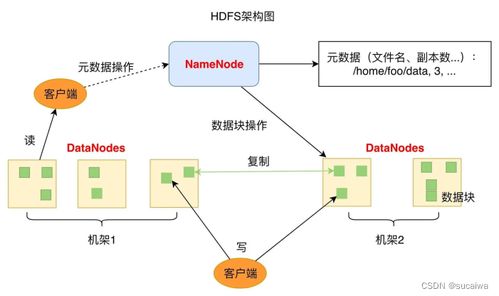
- 高容錯(cuò)性與可靠性:HDFS通過(guò)數(shù)據(jù)塊的多副本機(jī)制(默認(rèn)3副本),確保即使某個(gè)節(jié)點(diǎn)發(fā)生故障,數(shù)據(jù)也不會(huì)丟失。這種設(shè)計(jì)特別適合大規(guī)模集群環(huán)境,保障了數(shù)據(jù)存儲(chǔ)的持久性。
- 高吞吐量訪問(wèn):HDFS針對(duì)一次寫入、多次讀取的場(chǎng)景優(yōu)化,能夠高效處理海量數(shù)據(jù)的批處理任務(wù)。例如,在MapReduce、Spark等計(jì)算框架中,HDFS能提供穩(wěn)定的數(shù)據(jù)支持。
- 成本效益:HDFS可以部署在廉價(jià)的商用硬件上,通過(guò)橫向擴(kuò)展來(lái)增加存儲(chǔ)容量,避免了傳統(tǒng)存儲(chǔ)系統(tǒng)的高昂成本。
- 成熟的生態(tài)系統(tǒng):作為Hadoop生態(tài)的基石,HDFS與眾多大數(shù)據(jù)工具(如Hive、HBase、Flink)無(wú)縫集成,形成了完整的數(shù)據(jù)處理鏈條。
新技術(shù)浪潮下的挑戰(zhàn)與機(jī)遇
盡管云存儲(chǔ)(如AWS S3、Azure Blob Storage)和實(shí)時(shí)數(shù)據(jù)庫(kù)(如Kafka、Cassandra)在大數(shù)據(jù)領(lǐng)域嶄露頭角,但它們往往與HDFS形成互補(bǔ)而非替代關(guān)系:
- 云存儲(chǔ):適合冷數(shù)據(jù)備份或跨區(qū)域共享,但實(shí)時(shí)計(jì)算性能可能不及HDFS。
- 實(shí)時(shí)數(shù)據(jù)庫(kù):擅長(zhǎng)流處理,但缺乏HDFS的海量存儲(chǔ)能力。
HDFS通過(guò)持續(xù)演進(jìn)(如支持糾刪碼以降低存儲(chǔ)開(kāi)銷、優(yōu)化小文件處理)來(lái)應(yīng)對(duì)新需求,同時(shí)其“數(shù)據(jù)本地化”特性(將計(jì)算任務(wù)調(diào)度到數(shù)據(jù)所在節(jié)點(diǎn))仍是提升效率的關(guān)鍵。
數(shù)據(jù)處理與存儲(chǔ)服務(wù)的實(shí)踐場(chǎng)景
在實(shí)際應(yīng)用中,HDFS常作為數(shù)據(jù)湖的核心存儲(chǔ)層:
1. 數(shù)據(jù)采集與存儲(chǔ):將日志、交易數(shù)據(jù)等原始信息批量寫入HDFS,形成可追溯的數(shù)據(jù)基礎(chǔ)。
2. 批量處理:通過(guò)MapReduce或Spark對(duì)HDFS中的數(shù)據(jù)進(jìn)行ETL(提取、轉(zhuǎn)換、加載),生成結(jié)構(gòu)化數(shù)據(jù)集。
3. 混合架構(gòu):結(jié)合Kafka處理實(shí)時(shí)流數(shù)據(jù),并將結(jié)果持久化到HDFS,實(shí)現(xiàn)批流一體的數(shù)據(jù)處理。
例如,某電商平臺(tái)使用HDFS存儲(chǔ)歷史訂單數(shù)據(jù),通過(guò)Spark進(jìn)行用戶行為分析,同時(shí)用S3備份非活躍數(shù)據(jù),形成高效且經(jīng)濟(jì)的存儲(chǔ)體系。
未來(lái)展望
隨著AI和物聯(lián)網(wǎng)的興起,數(shù)據(jù)量呈現(xiàn)爆炸式增長(zhǎng)。HDFS的演進(jìn)方向可能包括:
- 更好地融合云原生技術(shù),支持彈性伸縮。
- 增強(qiáng)對(duì)非結(jié)構(gòu)化數(shù)據(jù)(如圖像、視頻)的管理能力。
- 優(yōu)化與內(nèi)存計(jì)算、GPU加速等新硬件的協(xié)作。
但無(wú)論如何,其核心設(shè)計(jì)理念——可靠、可擴(kuò)展、低成本——將繼續(xù)為大數(shù)據(jù)存儲(chǔ)奠定基石。
###
大數(shù)據(jù)的世界雖不斷有新星閃耀,但HDFS憑借其經(jīng)久考驗(yàn)的架構(gòu)和生態(tài)優(yōu)勢(shì),依然是存儲(chǔ)領(lǐng)域的“定海神針”。對(duì)于學(xué)習(xí)者而言,深入理解HDFS的原理與應(yīng)用,不僅是掌握大數(shù)據(jù)技術(shù)的必經(jīng)之路,更是應(yīng)對(duì)未來(lái)技術(shù)變革的堅(jiān)實(shí)基礎(chǔ)。在下一講中,我們將探索如何基于HDFS構(gòu)建數(shù)據(jù)處理管道,敬請(qǐng)期待!
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.51yyi.cn/product/79.html
更新時(shí)間:2026-04-14 07:33:53